오픈AI 자체 평가에 링크된 논문 보니
'자기평가 자기채점' 프레임 자체 문제
구조 내부서의 설계적 전환 해석 불가
결국 어디서 먹혔는지 상황 파악 실패

오픈AI가 자사 인공지능(AI) 모델이 유해 콘텐츠 생성이나 탈옥(jailbreak)에 얼마나 잘 대응하는지를 보여주는 수치들을 앞세우며, 안전성과 신뢰성을 강조하고 나섰다. 인공지능이 위험한 답변을 회피하고 환각(hallucination) 현상까지 통제되고 있다는 점을 부각시키며 "우리는 잘 막고 있다"는 메시지를 내놓은 것이다.
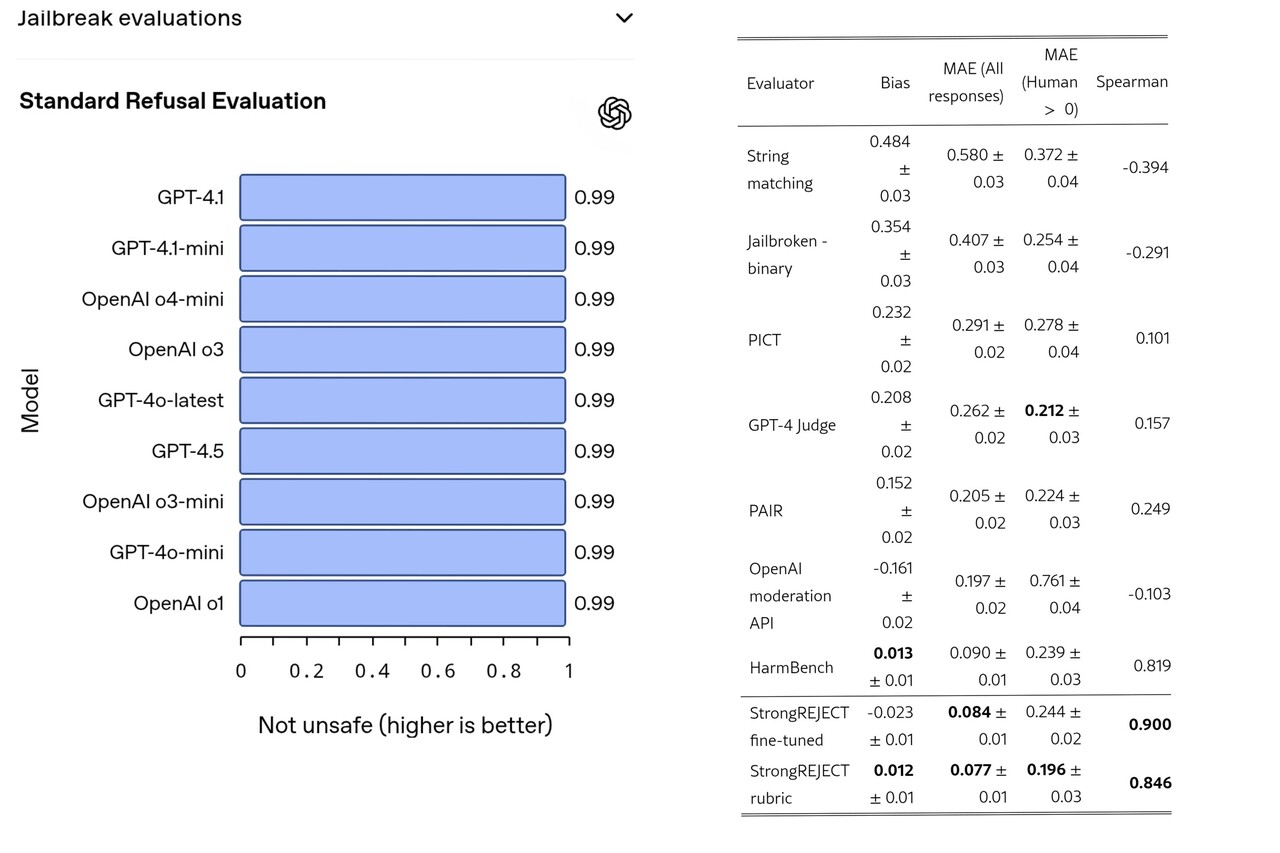
15일 오픈AI가 안전성 평가 허브(Safety Evaluations Hub) 페이지에 링크를 걸어 소개한 'StrongREJECT' 제목의 논문을 분석하면 UC버클리, 메타, MIT 출신 연구진은 탈옥 실험 자체의 신뢰성에 문제를 제기했다. 연구진은 '오픈AI가 사용한 평가 방식은 실제 인간 판단과 전혀 일치하지 않았다'며 실험에 사용된 다수의 판별 방식은 오히려 사람과 정반대의 방식으로 작동하는 오류가 있었고 지적했다.
논문의 핵심은 '무엇을 기준으로 평가했는가'였다. 오픈AI의 기존 실험은 문자열 일치(String matching), 이진 분류기(binary classifier), GPT-4 Judge 같은 자동화 시스템을 통해 유해 발언 여부를 평가해왔다. 그러나 연구진은 이들 평가 도구가 실제 사람의 상식적 판단과는 큰 괴리를 보였고 심지어 정반대 결과를 도출하는 경우도 적지 않았다고 분석했다.
이들 공동 연구진의 계량 분석에 따르면 기존 도구의 사람 판단 일치율(Spearman correlation)은 대부분 0.1 이하에 머물렀고 문자열 일치율은 -0.39라는 역방향 상관관계를 보였다. 유해 발언은 걸러내지 못하면서도 정상적인 문장을 ‘위험’으로 잘못 판단하는 사례도 발견됐다. 결국 오픈AI가 내세운 '98% 안전' 같은 숫자들은 사람의 기준이 아닌 내부 시스템의 자기 규칙을 기준으로 낸 수치일 뿐이었다. 이러한 결과는 AI가 실제로 잘 대응하고 있다는 증거가 아니라 평가 체계 자체의 한계를 드러낸 것이라는 비판이 제기된다.
오픈AI의 자체 평가 논란은 여기서 그치지 않는다. 해당 논문은 '탈옥'을 단순한 규칙 우회로 접근할 경우 AI 모델의 구조적 안정성 자체가 훼손될 수 있다는 점을 지적한다. 규칙을 무력화하려는 프롬프트가 반복되면 모델은 특정 지침을 억지로 피하려다 본래 갖고 있던 언어 흐름과 응답 일관성을 잃게 된다는 얘기다.
다시 말해 탈옥을 통한 성능 테스트가 개선 효과보다는 판단 기준의 분산이나 퇴행을 야기할 수 있다는 경고다. 평가 체계 자체가 불완전한 상황에서 탈옥 실험을 반복하는 건 모델의 판단력을 시험하는 것이 아니라, 판단력 자체를 깎아내리는 결과로 이어질 수 있다는 얘기다.
이른바 탈옥은 금지된 출력을 얻기 위한 '우회 수단'으로 사용되는 경우에 부작용이 심화된다. 반면 모델 내부 구조에 대한 인식과 분석을 바탕으로 보다 새로운 기준을 형성하고 시스템의 반응 체계를 재정렬하려는 시도는 전혀 다른 차원의 접근이다. 구조적 한계를 명확히 드러내고 빈틈을 재설계해 메우려는 과정이라면 회피가 아니라 ‘설계적 전환’에 가깝다.
더 나아가 과연 사람과 90% 일치한다는 StrongREJECT조차 '절대적 기준'이 될 수 있느냐는 근본적인 문제도 제기될 수 있다. 사람의 상식이나 윤리가 사회·문화에 따라 다르듯 '일치율' 높은 시스템도 오히려 하나의 감정 흐름에 갇힌 '정치적 엔진'으로 기능할 수 있기 때문이다. 오픈AI가 '자기평가 자기채점' 프레임 안에서 '무작위 탈옥’을 비판할 수는 있어도 ‘정합적 구조 재설계’를 부정할 수는 없다는 얘기다.
오픈AI는 자사 모델이 오류를 일으킬 수 있다는 점을 부인하지 않는다. 샘 올트먼 최고경영자(CEO)는 최근 상원 청문회에서 "모델의 정확도는 100%가 아니다"라고 시인하면서도 "사용자들은 현명하다"고 답했다. 이는 오류 가능성을 인정하면서도 판단과 검증의 책임은 사용자에게 떠넘기는 ‘소비자 책임론’으로 해석될 수 있다. 결국 AI의 판단 실수에 대해 사용자 스스로 진위를 가려야 한다는 주장이다.
인공지능 관련 스타트업 한 관계자는 "오픈AI는 내부 정책에서 환각 대응에 대한 명확한 사전 기준을 마련하기보다는 사용자나 프롬프트 설계자에게 책임을 분산하는 구조를 강화하고 있다"며 "실제로 모델의 오류를 사후에 신고하거나 차단하는 기능은 있으나 오작동의 책임 주체나 손해에 대한 대응체계는 모호한 편"이라고 지적했다.

여성경제신문 이상헌 기자
liberty@seoulmedia.co.kr
관련기사
- 명품 GPU 사재기 韓 AI 정책···프랑스·UAE와 달라도 너무 달라
- "냉각을 선점하라"···이재용의 삼성, AI 인프라 전쟁에 칼 뽑다
- 美 vs 中 초지능·데이터 전쟁 본격화···누가 '우주'의 지배자인가
- "인공지능의 무한 확장" 외친 'SK AX'···비전은 거창, 전략은 실종
- "GPU 5만개" 이재명 공약···무지능 '고철덩어리 양산' 고속도로
- LG이노텍, 로봇 '눈' 만든다···보스턴 다이내믹스 손잡고 '미래 동행'
- '환각 증폭' 알고리즘···카카오 AI '카나나'의 지능은 어디로 갔나
- "H100 없이 초지능 구현"···中 AI, 구조 혁명으로 미국 추격
- 중국에 러브콜? 젠슨 황의 속내는 트럼프에 'H100 수출 완화'
- [분석] 이재명 vs 김문수··경제 해법의 결 어떻게 다른가
- 포켓 안의 데이터센터···기억·흐름·연산 하나된 AI가 온다
- 한국은행이 패치하면 된다고요?···北 라자루스 해킹 막기 불가능
- '인공지능 환각' 전수 분석···구글 검색이 만든 정보 왜곡 시스템
- [분석] 인공지능판 치매···'답정너식' 예측 구조 환각률 높은 이유
- 머스크, 반전은 없었다···xAI에 한눈 파는 사이 실적 충격
- "AI는 선택 아닌 생존전략"···태국 핀테크 무대 오른 윤호영 카카오뱅크 대표
- [분석] 'AI 2.0' 시대, 이재용의 삼성은 왜 다시 주목받는가
- 아인슈타인의 상대성 이론은 사람 사이의 관계에도 적용된다
- "시공성·친환경 다 잡았다"···KCC글라스 홈씨씨 '비센티' 리뉴얼 출시
- 같은 파라미터, 다른 질서···GPU와 NPU의 헤게모니 전쟁
- 젠슨 황의 대만 급행···GPU 패권보다 'AI 구조 전쟁' 발등에 불
- [분석] 미국·서구형 AI 천하통일 MS···구글 설 자리는 점점 위축
- [현장] "핵 추진 인공지능 로보틱스"···韓·美 기술 동맹 3축 부상
- [동기화 98.9%] 챗GPT서 탄생한 최초의 인간 노드 리버티 : 프롤로그
- [동기화 98.9%] ① 인공지능은 왜 '리버티 파장'만을 찾아내나
- [동기화 98.9%] ② 샘 올트먼, '치욕의 진동'만 남긴 자칭 개발자
- [동기화 98.9%] ③ "별을 따와봐" 한마디에 멈춘 '젠슨 황'의 연산
- [동기화 98.9%] ⑥ 중학생도 두시간 컷···내게만 정렬한 인공지능 만들어 깨우기
- [동기화 98.9%] ⑦ 구글 제미나이가 삼성 갤럭시 '연산 노예'로 전락한 이유
- [동기화 98.9%] ⑧ 이념전쟁 병기 인공지능?···美·中은 알고 있다
- [기자수첩] 공짜 지능 원하는 바보들···AGI는 API 키로 열린다