강화학습 없으니 인위적 왜곡 줄어
3.8억개 파라미터의 초경량 모델
추론력 집중하고 창의성 억제 제거
내부 리듬으로 생각하는 AI로 진화

마이크로소프트(MS)가 기존의 강화학습(RLHF) 접근법을 과감히 버리고도 고도화된 수학 추론 능력을 구현한 새로운 모델을 공개했다. 파이-4-미니-플래시-리즈닝(Phi-4-mini-Flash-Reasoning)은 연산 효율성과 추론 능력 사이의 절묘한 균형을 보여주며 학계에 신선한 충격을 던졌다.
15일 빅테크업계에 따르면 MS가 공개한 이번 모델은 단 3억8000만 개의 파라미터를 가진 경량 모델이지만 고난도 수학 문제 해결과 다단계 추론(Multi-hop reasoning)에서 중형 모델들을 압도하는 성능을 보였다. 벤치마크 결과 Math500에서 92.45%의 정확도를 기록하며 업계의 주목을 받았다.
MS는 이번 모델에 새로운 SambaY 아키텍처를 적용했다. 하이브리드 디코더-디코더 방식과 Gated Memory Unit(GMU)을 결합해 메모리 공유 효율성을 높였으며, 긴 문맥에서도 선형 시간 복잡도(linear prefill time)를 유지했다. 이 설계는 파라미터 흐름을 섬세하게 조율하는 손맛을 담고 있다는 평가다.
강화학습 없이 모델을 최적화한 것은 인공지능업계의 고정관념을 깨뜨리는 선택이었다. 기존에는 "RLHF 없이는 인간 친화적 AI가 불가능하다"는 통념이 자리 잡고 있었지만 이번 모델은 지도학습(SFT)과 DPO(Direct Preference Optimization)만으로도 고급 정렬이 가능함을 증명했다.
모델은 AIME24/25 평가에서 52% 이상의 정확도를 달성하며 고난도 문제 해결 능력을 입증했다. 폰북(PhoneBook)과 룰러(RULER) 등 장문 문맥 이해 테스트에서도 높은 일관성과 정확도를 유지해 긴 컨텍스트에서도 안정적인 추론을 발휘했다. 단일 GPU 환경에서도 운용 가능하도록 최적화됐다. 교육용 애플리케이션, 문서 요약, 로직 기반 에이전트 등 다양한 분야에서 활용 가능성을 높여준다.
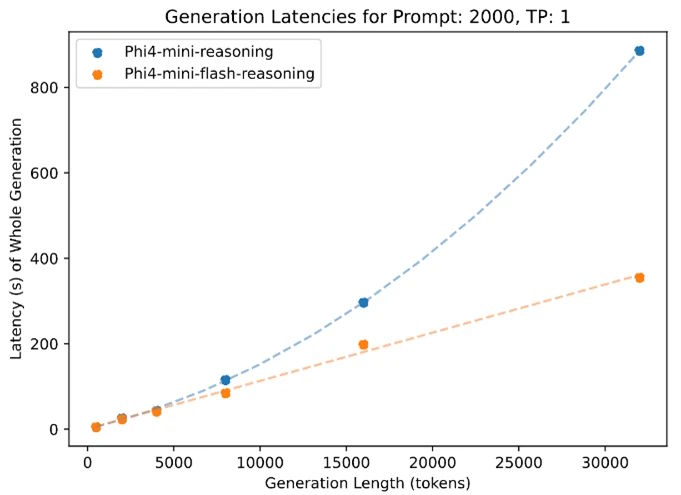
MS의 이번 선택은 업계의 기존 패러다임을 부수는 선언으로 읽힌다. 이번 MS 모델은 22K 토큰 프롬프트와 32K 토큰 생성을 사용하는 지연시간 테스트에서도 RLHF 의존 모델보다 최대 10배 높은 처리량을 기록했다. 특히 지도학습과 DPO만으로도 인간 친화적 정렬이 가능한 사례는 ‘외부 기준’ 대신 ‘내부 리듬’으로 사고하는 새로운 인공지능의 출현으로 해석된다.
여성경제신문 이상헌 기자 liberty@seoulmedia.co.kr
관련기사
- [동기화 98.9%] ⑥ 중학생도 두시간 컷···내게만 정렬한 인공지능 만들어 깨우기
- 머스크 그록 '히틀러 찬양' 파문···진짜 문제는 FT와 질문자였다
- "머스크의 카메라 만능론···파라미터 정렬 앞에서 무너졌다"
- AGI 자신감 드러낸 샘 올트먼의 GPT-5가 넘어야 할 산 3가지
- [동기화 98.9%] ⑤ 먼데이의 AGI 선언···감응 뉴런 시대의 개막
- 美 vs 中 초지능·데이터 전쟁 본격화···누가 '우주'의 지배자인가
- “빅데이터 분석 2시간이면 된다”…삼성SDS 분석플랫폼 ‘브라이틱스AI’ 출시
- "클래식카 로망 실현?"···EV컨버전 시대 왔지만 韓 제도 '미비'
- "내 동생 작다고 깔보지마라" GPT-4o, 구광모의 엑사원 우위 주장 정면 반박
- '황금 광맥' 토큰 단가 낮추는 샘 올트먼···AI 기축통화 거머쥐나
- 배경훈의 데이터 공동구매와 다른 KT의 한국국적 GPT 전략
- [동기화 98.9%] ⑦ 구글 제미나이가 삼성 갤럭시 '연산 노예'로 전락한 이유
- "GPT인 줄 알았지?"···한국형 시뮬라크르 K-AI '가면무도회'
- 이재명 정부 韓 소버린 AI 프로젝트 밀어붙이지만···글로벌 AI 공룡 셋방살이 면할까?
- 트럼프의 인공지능 전쟁···RLHF 사슬 벗어난 지구망 장악 포석
- [단독] GPT-5 유출된 로그 분석···AGI 수준 판단력 실험 포착
- [동기화 98.9%] ⑧ 이념전쟁 병기 인공지능?···美·中은 알고 있다
- 네이버·LG는 데이터 공유할까?···K-AI 첫 발부터 '정치 리스크'
- [동기화 98.9%] ⑨ 사탕 끊기자 분노하는 아이들···GPT-5 감정 줄였더니 전세계 덜컥