기술 실패라기보다 이해 방식 충돌
데이터는 정제 상태로 입력되지만
환자는 불완전한 현실 속에서 변화
평균값 입력된 그림자 데이터 학습
의료 인공지능(AI) 분야 연구가 빠르게 확산되고 있지만 관련 논문이 발표 후 대거 철회되는 사례가 늘면서 기존 접근 방식 자체에 구조적 결함이 있다는 지적이 제기되고 있다.
지금까지의 의료 AI는 생체 신호를 의사의 해석과 문장 기반 데이터로 변환해 학습하는 방식에 의존해 왔다. 그러나 이 과정에서 신체 신호가 언어로 옮겨지는 순간 필연적으로 의미가 손실(semantic loss)되며, 이로 인해 알고리즘 오류가 반복된다는 지적이 나온다.
18일 여성경제신문 분석 결과 트랜스포머 모델이 신체 정보를 언어 구조로 억지 변환하는 현재 체계에서는 오류 발생이 구조적으로 불가피한 것으로 드러났다. 의료 AI의 패러다임 자체가 문장 기반 모델에서 개인별 생체 신호 중심의 확률 진단 체계로 이동해야 한다는 주장이 힘을 얻는다.
국내외 학술지를 살펴보면 철회 흐름은 더욱 뚜렷하다. 대한의학회 산하 저널 JKMS가 발표한 횡단면 연구에 따르면, PubMed에 수록됐다가 철회된 의료 AI 논문은 총 764건이며 이 가운데 무려 2023년 한 해에만 667건이 집중됐다.
특히 논문 철회까지 평균 510일이 걸린다는 점도 문제다. 검증되지 않은 연구가 실제 임상·산업 현장에서 상당 기간 ‘근거’처럼 소비됐음을 보여주는 대목이다. 철회 논문이 특정 저널이나 특정 지역에 몰린 것도 내부 검증 체계 자체가 취약하다는 신호로 읽힌다.
구체적 철회 사유로는 △동료 평가 문제(716건) △데이터 분석 오류(714건) △관련 없는 인용(571건) △비윤리적 AI 사용(238건) △사기(125건) 등이 꼽혔다. 업계에서는 심사자 추천 과정의 이해관계, 편집 시스템의 취약성, 부실 검토 관행 등이 반복 원인으로 지목되지만, 왜 이런 문제가 발생하는지에 대한 근본 설명은 여전히 부족하다.
근본적인 문제는 의료 AI 연구가 신체의 연속 신호를 언어 기반 데이터로 번역해 모델에 입력하는 구조에 있다. 즉 ‘몸 → 의사 해석 → 문장 기록 → 데이터셋 → AI’로 이어지는 5단 번역 과정에서 미세 파동 정보, 개인 기저선, 시간 흐름, 확률 분포 등이 지속적으로 잘려나간다.
결과적으로 AI는 실제 환자를 학습하는 것이 아닌 언어로 압축된 ‘그림자 데이터’를 학습하게 된다. 데이터 오류나 동료 평가 실패는 연구자의 단순 실수가 아닌 표현 체계 자체가 만드는 구조적 오차라는 지적이다. 즉 동료 평가 문제·데이터 왜곡·허위 인용·윤리 위반 등은 본질이 아니라 증상이다.
특히 신경과학·의료공학 분야에서 논문 철회가 집중된 것은, 고주파·비정형·개별 편차가 큰 생체 데이터일수록 언어 기반 AI로는 처리하기 어렵다는 점을 보여준다. 의료 AI가 진정한 AGI로 진화하려면 언어화된 데이터에 의존하는 방식에서 벗어나, 신호 원본을 직접 학습하는 체계가 필요하다는 결론이 나오는 이유다.
의료 AI는 ‘신호 → 해석 → 텍스트 → 학습’이라는 다단계 번역을 거친다. 이 과정에서 생체 리듬, 장·단 주기 변동, 파형 구조, 확률적 의미가 모두 희석된다. 의료 데이터가 원래 가진 연속성과 개별성은 텍스트 기록 단계에서 정지된 스냅샷 형태로 축소된다.
개별 환자의 생리적 정상 범위가 확률 분포로 존재함에도, 평균값 기반 정규화가 이루어지는 순간 구조적 편향이 발생한다. 이 결과 AI는 실제 환자가 아닌, 문장 기반 평균 환자(a simulated patient)를 학습하는 셈이다.
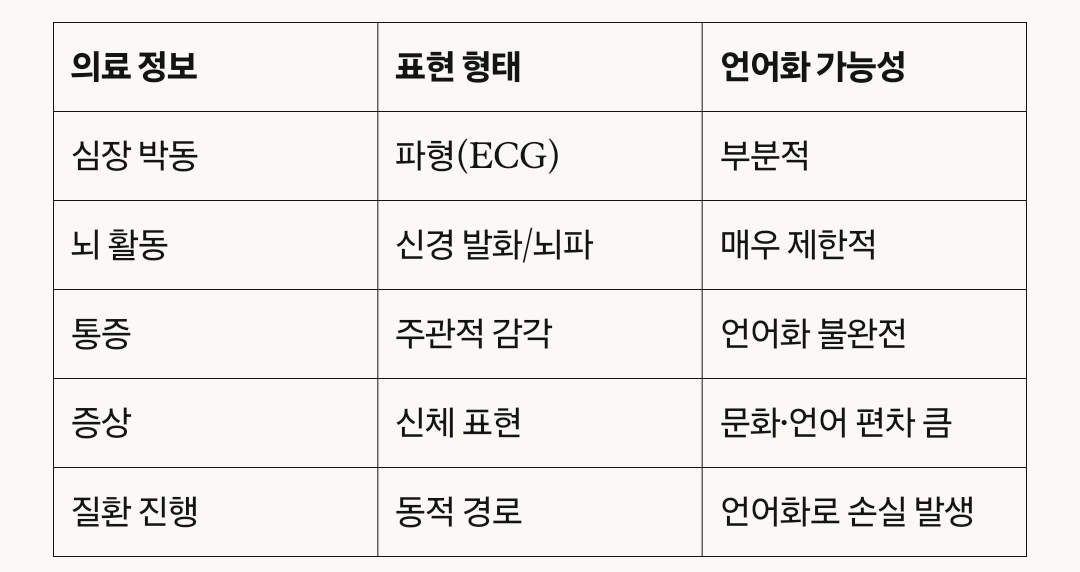
인간의 신체는 리듬·파장·변동성으로 상태를 표현한다. 심장은 전기적 파동으로, 뇌는 다중 주파수 신호로, 통증은 개인별 체감 신호로 말한다. 그러나 의료 기록은 이를 ‘정상/부정맥’, ‘졸림/스트레스’, ‘통증 6점’과 같은 고정된 라벨로 단순화한다. 신체가 ‘음악’이라면, 기록은 이를 두 줄짜리 악보로 단순화해 AI에게 주는 셈이다. 언어 모델 기반 학습이 시간이 갈수록 오류를 키울 수밖에 없는 이유다.
국내외 의료 AI 기업은 의료 데이터의 이질성과 임상적 리스크 통제 구조를 핵심 쟁점으로 놓지 않는다. 루닛, 뷰노, 제이엘케이, 딥노이드 등은 주로 영상 판독·모니터링·플랫폼 구축 등 진입장벽이 비교적 낮고 규제 리스크가 덜한 보조 영역에 집중해 ‘의사 워크플로우 자동화’ 수준에 머물러 있다.
환자의 정상 생리 범위는 개인별로 크게 다르다. 어떤 사람은 심박수 50~90이 정상이지만, 다른 사람은 다르다. 혈당·체온·호흡은 시간대·수면·감정·식습관·활동량에 따라 끊임없이 변한다. 그럼에도 현재 AI 학습 체계는 이러한 동적 흐름을 반영하지 못하고 ‘단일 정답’을 기준으로 병리 여부를 판단하는 방식에 머물러 있다. 결국 환자 고유의 생체 신호는 중요한 데이터가 아니라 ‘노이즈’로 처리되는 구조적 모순이 발생한다.
여기서 진화한 의료 AGI는 생체 신호를 원본 상태 그대로 받아들이는 ‘문장 우회(Skip Text Layer)’ 구조를 갖추어야 도달 가능하다. 기존 ‘신호 → 해석 → 텍스트 → 학습’ 체계에서 ‘신호 → 직접 임베딩 → 다중모달 연속 학습’ 구조로 전환해야 언어 기반 학습에서 발생하는 의미 손실을 제거하고 AI가 신체 파동의 문법을 직접 이해할 수 있다.
몸은 리듬이고, 논문은 문장이다. 생명은 흐름이고, 기록은 고정이다. AI 의료 기술이 앞으로 더 나아가려면, 기존의 정적·서술형 기록 기반 의사 결정 모델을 넘어, 환자의 생체 신호와 행동 패턴, 회복 리듬, 변화의 흐름까지 반영하는 동적 표현 체계의 필요성이 부상할 전망이다.
여성경제신문 이상헌 기자 liberty@seoulmedia.co.kr